에포크와 배치(Epoch and Batch) [에포크와 배치] 모든 훈련 데이터를 1회 학습하는 것을 1에포크(epoch)라고 함.훈련 데이터의 샘플은 여러개로 묶여서 학습 되는데 이 샘플의 묶음을 배치(batch)라고 함.1 epoch 에 이용되는 훈련 데이터는 여러 개의 batch로 분할됨. 배치 사이즈(batch size)는 하나의 batch에 포함되는 샘플의 수.가중치와 편향을 수정하는 간격이라고도 함.배치 사이즈가 너무 크면 학습 속도가 느려지고, 너무 작으면 각 실행값의 편차가 생겨 전체 결과값이 불안정해질 수 있음.따라서 배치 사이즈는 학습 효율에 큰 영향을 주기 때문에 중요함. [배치 사이즈에 따른 학습의 종류] 1. 배치 학습 배치 사이즈 == 전체 훈련 데이터의 수 1 epoch (전체 데이터를 한번다보고)마다 가중치와 편향을 수.. AI/딥러닝 기초 5년 전
최적화 알고리즘(Optimizer) [최적화 알고리즘 (Optimizer)] 효율적이고 정확하게 전역 최적해에 도착하기 위해 최적화 알고리즘의 선택은 중요. 1. 확률적 경사 하강법(Stochastic Gradient Descent, SGD) 수정할 때마다 샘플을 무작위로 선택. 장점기울기 수정 시 훈련 데이터 중에서 무작위로 샘플을 선택하기 때문에 국소 최적해에 잘 빠지지 않음.또한 식이 매우 간단. 단점다른 알고리즘처럼 학습률을 자동으로 조정해주는 파라미터가 없어 수정량의 유연한 조정이 불가함. 2. 모멘텀(Momentum) SGD에 관성을 더한 알고리즘. 는 관성의 크기를 결정하는 모멘텀 상수.는 이전 회차의 수정량. 장점관성항을 더함으로써 새로운 수정량은 이전까지의 수정량으로부터 영향을 받게 됨.그렇기에 수정량이 급격하게 변화하는 .. AI/딥러닝 기초 5년 전
은닉층 기울기 구하기 층첨자 뉴런의 수 입력층i l 은닉층 j m 출력층 k n [은닉층 기울기 구하기] 은닉층 뉴런 가중치 기울기 구하기 : 오차 E를 가중치 로 편미분한 를 구함. 는 은닉층의 활성화 함수 편미분으로 구할 수 있음. 편향 기울기 구하기 : 오차 E를 편향 로 편미분한 를 구함. 앞 층으로 전파할 구하기 : 앞층에 은닉층이 더 있을 경우 다음을 구해 전파시킴. AI/딥러닝 기초 5년 전
출력층 기울기 구하기 층첨자 뉴런의 수 입력층i l 은닉층 j m 출력층 k n [출력층 기울기 구하기] 출력층 뉴런 가중치 기울기 구하기 : 오차 E를 가중치 로 편미분한 를 구함. 편향 기울기 구하기 : 오차 E를 편향 로 편미분한 를 구함. 출력층에서 입력값 기울기 : 앞 층의 은닉층에서의 연산을 위해 출력층에서 미리 (은닉층의 출력기울기)를 계산함. AI/딥러닝 기초 5년 전
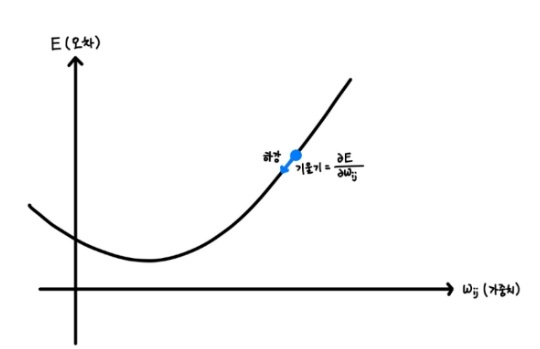
경사 하강법(Gradient Descent) [경사 하강법 (Gradient Decent)] 역전파에서 경사항강법을 통해 weight, bias 수정량을 결정. [역전파에서 경사 하강법] 실제로는 위와 같이 그래프 곡선 형태를 알기 어렵기에 오차가 최소가 되는 방향으로 조금씩 가중치를 변화시켜 감.오차가 하강하도록 변화시키면 오차는 줄여짐. 각 weight와 bias의 변화량은 이 곡선의 기울기로 결정됨.우선 모든 weight와 bias에 대한 오차의 기울기를 구해야 함. [국소 최적해와 전역 최적해] 가끔 위와 같이 국소 최적해(local minima)에 빠져버려 더 이상 weight 수정을 하지 않고 전역 최적해(global minima)에 도달하지 못하는 경우도 있음.국소 최적해를 피하기 위한 다양한 조정은 최적화 알고리즘을 통해 가능함. 간.. AI/딥러닝 기초 5년 전
손실함수(Loss function) [손실함수 (Loss function)] 출력값과 정답의 오차를 정의하는 함수.딥러닝에서 아래 두가지 손실함수가 많이 쓰임. 1. 오차제곱합 (Sum of Squares for Error, SSE) 출력층의 모든 뉴런에서 출력값과 정담의 차이를 제곱하고 이 값들을 모두 합함. E : 오차제곱의 합yk : 출력층의 각 출력값,tk : 정답 1/2 은 미분을 쉽게하기 위해 존재. 신경망의 출력값이 정답과 어느정도 일치하는지 정량화 가능.출력값과 정답이 연속적인 수치인 경우에 잘 맞기 때문에 회귀에서 자주 사용됨. [코드]1234import numpy as np def square_sum(y, t): return 1.0 / 2.0 * np.sum(np.square(y-t))cs 2. 교차 엔프로피 오차 (Cr.. AI/딥러닝 기초 5년 전
훈련 데이터와 테스트 데이터(Training data & Test data) [훈련 데이터와 테스트 데이터 (Training data & Test data)] 훈련 데이터는 신경망 학습에 이용.테스트 데이터는 학습결과 검증에 활용. 여러 개의 입력값과 정답의 짝(샘플)로 구성.보통 훈련 데이터의 샘플 수를 테스트 데이터의 샘플 수보다 많게 설정. 회귀 문제 정답 형태[ 0.23 -1.23 5.44 3.04 -0.81 ] 분류 문제 정답 형태[ 0 0 1 0 0 ] 하나만 1이고 나머지는 0인 수치 벡터를 one-hot encoding 이라고 부름. AI/딥러닝 기초 5년 전
학습규칙 & 역전파(Backpropagation) [학습규칙] :신경망이 학습할 때 결합강도가 어느 정도로 변화하는지 설명한 것. 1. 헵의 규칙 (Hebbian rule) 심리학자 Donald Hebb이 주장한 뇌의 시냅스 가소성에 관한 법칙.가소성이란 변화된 상태가 계쏙 유지되는 성질을 의미함. 헵의 규칙은 시냅스 앞쪽의 신경세포가 흥분하고 이에 따라 시냅스 뒤쪽 신경세포가 흥분하면 시냅스의 전달효율이 강화된다는 주장에 근거.반대로, 장기간 흥분하지 않으면 그 시냅스의 전달 효율도 감퇴. 결합강도(가중치)의 변화량은 시냅스 앞쪽 뉴런 출력 yi, 시냅스 뒤쪽 뉴런의 출력 yj 로 나타낼 수 있음.감마는 상수. yi가 yj와 함께 커지면 결합 강도가 크게 증가됨.시냅스 전후 뉴런의 흥분이 반복적으로 발생하면 이후부터는 시냅스에서 정보가 점차 효율적으로.. AI/딥러닝 기초 5년 전