
Series
pandas 기본 객체 중 하나
numpy의 ndarray를 기반으로 인덱싱 기능을 추가하여 1차원 배열을 나타냄.
index를 지정하지 않을 시, 기본적으로 ndarray와 같이 0-based 인덱스 생성
지정할 경우, 명시적으로 지정된 index 를 사용.
같은 타입의 0개 이상의 데이터를 가질 수 있음.
data로만 사용하기
index는 기본적으로 0부터 자동적으로 생성.

왼쪽이 인덱스이고 오른쪽이 데이터임.
자동적으로 인덱스가 붙은것을 확인할 수 있다.

데이터의 타입도 자동으로 생성함.

위와 같이 np를 이용해서 생성도 가능함.
data, index 함께 명시하기
pd.Series( data=None, index=None, dtype=None, name=None, copy=False, fastpath=False, )
pd.Series는 위와 같은 파라미터를 가짐.


인덱스는 숫자뿐아니라 문자열로도 지정이 가능하다.
data, index, data type 함께 명시하기

dtype을 지정하지않으면 os에 맞게 자동으로 타입을 할당함.
메모리 최적화(optimize)를 위하여 직접적으로 지정해줄 수 있다.

인덱스 활용하기
index : index만 가져오기
values : values만 가져오기
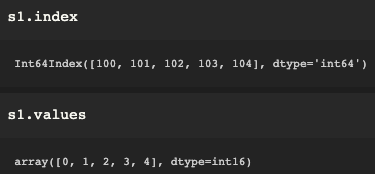
인덱스를 통한 데이터 접근

인덱스 0으로 접근하면 0에 해당하는 인덱스값이 존재하지 않으므로 keyerror가 나타난다.
존재하는 인덱스인 104를 넣으면 정상적으로 결과를 얻을 수 있다.
인덱스를 통한 데이터 업데이트

위에서 존재하지않았던 0 인덱스에 대해서 새로운 데이터를 저장해주면
에러없이 새롭게 저장이 가능하다. ==> 업데이트

인덱스 재사용하기

기존에 존재하던 s1의 인덱스를 새롭게 생성한 s2의 인덱스에 재사용할 수 있다.
index를 활용하여 멀티플한 값에 접근하기

접근하고자하는 인덱스를 리스트로 묶어 보내면 된다.
이 때 반환형태는 새로운 series 형태로 인덱스를 포함하여 반환한다.
위 내용은 fastcampus 강의 내용을 정리한 것입니다.
'AI > 데이터분석' 카테고리의 다른 글
| [pandas] series 데이터 연산하기 (0) | 2020.01.30 |
|---|---|
| [pandas] series 데이터 심플분석 (개수, 빈도 등) (0) | 2020.01.30 |
| [matplotlib] 그래프 그리기 (0) | 2020.01.22 |
| [Numpy] linalg 서브모듈 선형대수 연산 (0) | 2020.01.22 |
| [Numpy] Boolean indexing (0) | 2020.01.20 |
